Proyecto Final del Curso de Big Data Analytics
Segmentación de Clientes de un e-commerce con Fuzzy C-means en Herramientas Big Data
Equipo: Irpiri Agreda, Carlos Fabbri, Jazmín Wong
Esta es la página principal del proyecto de Segmentación de Clientes de un e-Commerce con Fuzzy C-means. El proyecto consiste en la utilización de dos herramientas distintas de Big Data, MRJob y Spark, para realizar la segmentación de clientes. Se presenta código implementado en Python y PySpark en donde se demuestran preprocesamiento. Luego, la implementación de la técnica se ha elaborado en MRJob. Finalmente, los resultados, presentados con ayuda de gráficos, se encuentran en formato de Python Notebook. El proyecto tiene como objetivo demostrar la viabilidad de implementación de la técnica Fuzzy C-means en la herramienta MRJob y el potencial de Spark como ambiente de preprocesamiento de datos de gran volumen.
El proyecto está separado en varias páginas: Problema, Abordaje, Preprocesamiento, Implementación en MRJob, Resultados y Conclusiones.
- Problema
- Abordaje
- Preprocesamiento
(Ejecución de todo el preprocesamiento puede tomar 10 minutos) - Implementación en MRJob
Ejecutar desde terminal asegurando que los archivos datos_pca.csv y export-1.txt se encuentran en la misma ruta.python MrJobFuzzy_Convergencia_Final1.py datos_pca.csv(Ejecución puede tomar 5-10 minutos y en promedio converge en 3 iteraciones)

- Resultados
- Conclusiones
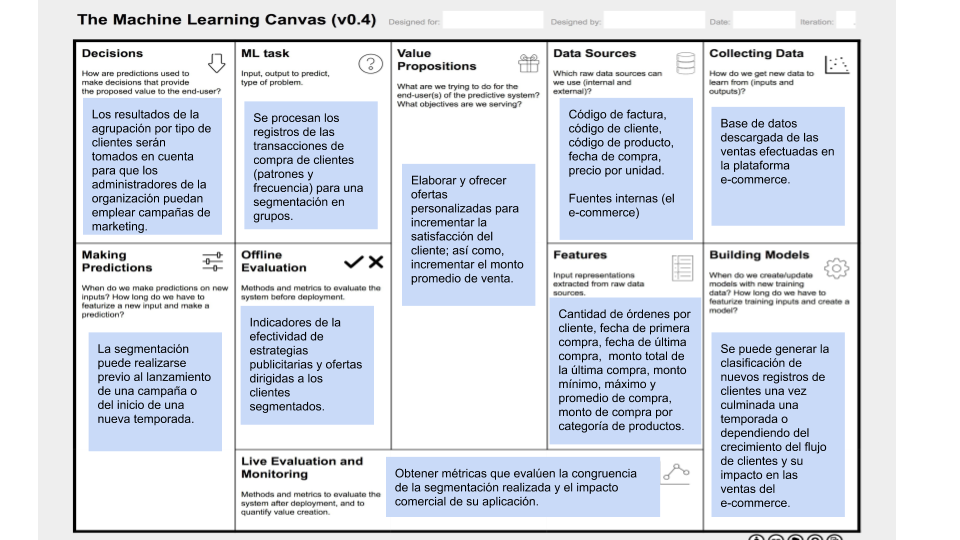
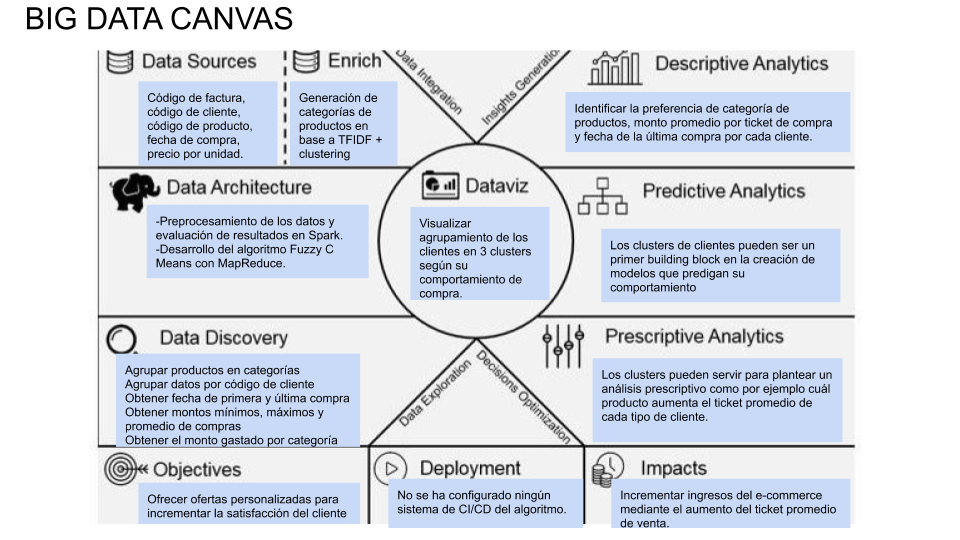
Adicionalmente, se elaboró el Machine Learning Canvas y el Big Data Canvas de la solución planteada.
Referencias
Además de las fuentes citadas en el archivo de Preprocesamiento y Resultados, también se revisaron:
- https://www.kaggle.com/prateekk94/fuzzy-c-means-clustering-on-iris-dataset
- https://github.com/gabrielspmoreira/kmeans_mapreduce_thunders